Java Generics and Collections
Collections are about how to store and manage elements in a data structure. It includes List, Set, Queue, and Map. Generics is about how to maintain element type in collections to be type-safe. That is the reason why these two topics are always staying together.
Generics
Java generics are introduced from Java 5. The purpose of using generics is to enable you to mark your intent of using a class, method, or interface with a particular data type. Generics add
compile-time safety to collections. By this way, a type inconsistency may be found in an early time, rather than in the run time. Generics can be applied to a class, an interface, a method, and even a constructor. They are called generic classes, generic interface, generic methods, or generic constructors.
The key for Generics is to declare type parameters, it is a placeholder that is replaced by an actual type in the compiling time. For an instance, List<String> is a parameterised type, which stands for a list that contains String alone, then the instance must host String alone, i.e new ArrayList<String>().
Generic type parameter declaration
Type parameter follows a naming convention, i.e. <T>, a single capital character. Type parameters can be declared with a class, a constructor, an interface, or a method.
For a generic class/interface, it declares its generic types parameter just after its class/interface name;
For a generic method, it declares its own type parameter just after the access modifier before its return type. This is important, for otherwise, the compiler may don't know what return type it is.
Type argument → Type parameter; when compiling using actual type to replace the type parameter.
The compiler may replace type parameters using actual types presented in generic type argument, or infer it from the real data types.
For class(interface) generics: a type parameter is inferred from a parameterised type, like new List<Integer> ints = ArrayList<>();
For method generics: type parameter is inferred from the real data type, from the input arguments or returned value type;
Type erasure in the runtime
After compilation, the generic type will be replaced by an Object type or its generic boundary class type. The compiler generates a single version of a compiled class file for the generic class/interface, but not one for a generic class or one for a raw class. So during the runtime, there are no generic types. Java Generics is a compiling time check, to verify the object types are consistent in the collection as we intend to.
Bounded generic types
The purpose is to restrict types that can be used as a type-argument by putting a boundary.
A type parameter can have multiple boundary types, i.e. one class type and many interface types. It means that a type-argument must satisfy all types of constraints.
Upper-bounded generic type:
<T extends Number>: meaning that type argument is a subtype of Number type.
Lower-bounded generic type:
<T super Number>: meaning that type argument is a supertype of Number type.
A generic class can extend another generic class or interface.
A generic class may extend from another generic class, but it must pass a type argument to the type parameter of its base class. Otherwise, it won't be compiled.
Class ArrayList<E> implements List<E>
The type parameter E is passed to its base class as a type argument.
The inheritance doesn't apply to generic arguments.
A rule: Reference generic type must be identical to the instance generic type.
List<Object> objects = new ArrayList<Integer>();
Although ArrayList is-a List, and therefore an ArrayList instance can be assigned to a List reference variable. However, this concept doesn't work with generic arguments. The above won't compile.
I think the reason because this violates the purpose of the generics, checking the consistency of the element types.
List<Object> objects = new ArrayList<Object>();
//the above compile correclty.
Non-generic class or interface extends from a generic class
A non-generic class can extend another generic class. However, it needs to pass type argument(a type of instance) to its base class.
class Parcel<T> {}
class NonGenericPhoneParcel extends Parcel<Phone>{}
A non-generic class can implement a generic interface by replacing its type parameters with actual types. The same as the above
Using wildcard
A wildcard(?) type parameter stands for any object types, or say a unknow type. A wildcard type parameter can be constrained by an upper boundary or a lower boundary.
List<?> list = new ArrayList<String>(); //this is valid
List<Object> list = new ArrayList<String>()//this is not valid. must be identical.
So the wildcard stands for any type of objects alone.
Adding objects to a wildcard defined collection is not allowed.
List<?> list = new ArrayList<String>(); //this is valid
list.add(new Book()); //this won't complile
The above List<?> accepts any type of objects; Compiler, therefore, cannot make sure of type consistency. So it simply prevents it from compiling. However, if we use it as a method argument, then it gives a sort of flexibility to accept a group of object types, meanwhile, you get a data consistency protection because in the method the wild card collection cannot be modified.
Using a wildcard as a method argument
void method(List<?> list){
//you can traverse all elements of input list.
list.forEach(System.out::println);
//but you cannot add element to it.
list.add(new Object())//compiling error here
}
However, you lose the possibility to add a new element within the method; it will cause a compilation error.
Upper-bounded wildcard
For upper-bounded wildcard, you can read over the collection, but you cannot add an element. The problem is because an upper-bounded wildcard is open for all sub-types of the upper bound, so compiler prevents adding a new element.
List<? extends Gift> list = new List<Gift>(); //valid;
List<? extends Gift> list = new List<Book>();//valid
List<? extends Gift> list = new List<Follower>();//valid
However, you cannot add a new element in the lists mentioned above; it causes compilation errors.
It is good for the method input argument, which makes the method accepts a group of object types.
void method(List<? extends Number> list){
list.forEach(System.out::println);
}
Lower-bounded wildcard
For lower-bounded wildcard, you can add a new element, i.e. boundary type and its subtypes; you can loop over each element, but via Object type. Actually, it sounds weird.
<? super Type> a supertype of a class type, including the boundary.
List<? super Gift> list = new ArrayList<Gift>();
List<? super Gift> list = new ArrayList<Object>()
You can add new element Gift type and its subtypes.
for(Object gift:list){}
List<? super Gift> list; read as Object, add Gift and its subtypes.
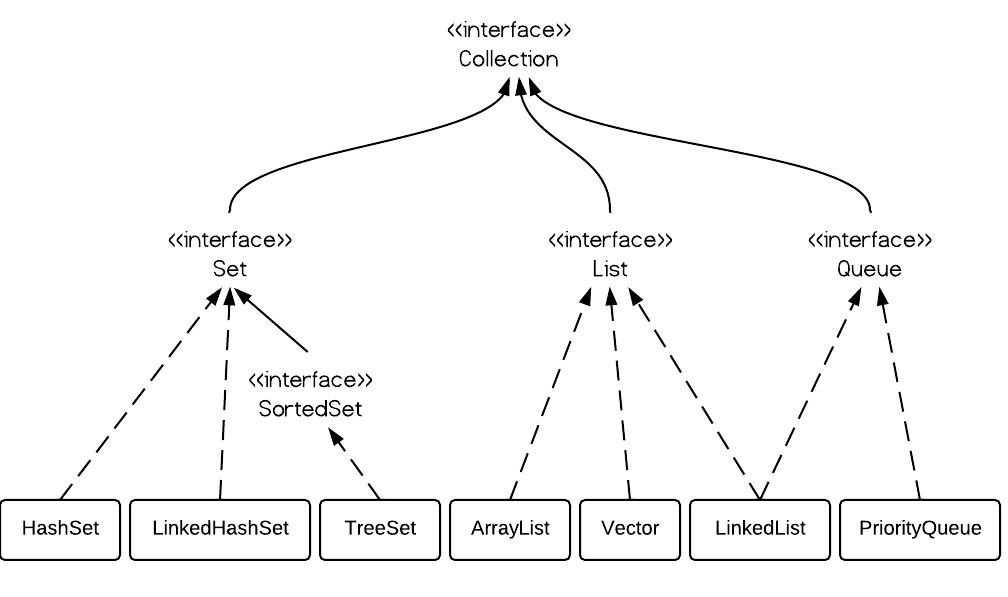
Collection
The collection is a data structure, to hold a group of objects(elements); and data structure functionalities, like add, insert, remove, sorting, etc.
Set,
List and
Queue Interface
extends from
Collection Interface extends
Iterable Interface. Therefore, Set, List and Queue are both collections and iterable. The map doesn't implement Collection interface, but it is a part of java Collection and considered as a kind of Collection.
Set maintains a collection of unique elements.
List maintains a collection of elements, may be duplicated.
Concrete implementations:
Set:
HashSet(not ordered, sorted by hashcode),
LinkedHashSet(ordered), and
TreeSet(sorted by comparable)
List:
ArrayList(ordered) and
LinkedList(ordered)
Queue: LinkedList(ordered) (LinkedList
implements Queue interface
)
Ordered: retrieving elements in order as they are added. All lists are ordered, but not HashSet and TreeSet. When needing an ordered set, then implementing LinkedHashSet. It is internally implemented as a linked list.
Sorted: elements are sorted, and they may need to implement
Comparable interface, like TreeSet. Otherwise, the client has to provide a comparator as instantiating it. Please note: HashSet is implemented as HashMap, it was sorted by the hash code of an element, which is translated into an index number used as a key value of the map. That is why HashSet has no guarantee of order but sorted by the hashcode.
ArrayList supports random access, for internally it is implemented by an Array so that it supports accessing element directly by array indexing. LinkedList supports sequence access, for underlying, it implemented a double-linked list, each node(holding the elements) contains pointers pointing to the previous element and next element. When accessing one of the elements of LinkedList, it has to traverse from the head to the tail, until finding a matched element.
HashSet retrieving uses hashcode, in some sense it is a kind of indexing, but invoking hashcode-index calculation, and when more than one elements sharing the same index, it may invoke equals method to locate the element.
TreeSet →NavigableSet→SortedSet→Set
TreeSet is sorted in natural order, or by an external custom comparator. TreeSet offers navigable and sorted APIs.
ArrayList vs LinkedList:
ArrayList is internally implemented as an array, so it supports random accessing. However, its array size is not mutable, it needs frequently re-instantiate a new array according to current array size and capacity factor, and also resulting in extra unused memory space. In a linked list, this can be easily by reset the node previous and next pointer.
LinkedList →Dequeue→Queue
LinkedList implements Deque that implements Queue. LinkedList is, therefore, be used to implement Queue and Stack.
PriorityQueue → Queue
The purpose of PriorityQueue is First priority first out. PriorityQueue is sorted according to element natural order or an external comparator.
From the view of insertion and removal, the linked list gives much better performance for implementing a Queue. It doesn't need to swap the buckets but simply cutting off a pointer and re-pointing to a new bucket.
Map
The map is packaged within the collections. The Map is an interface. It is a type of collection, although it doesn't implement the Collection interface.
HashMap:
The Map is ordered by the key hashcode, which is translated into an Index pointing to one bucket of the map. So the Map will rearrange the order of the elements.
boolean containsKey(key)
boolean containsValue(value)
V get(Object key): get value from its key
Set<K> keySet();
Collection<V> values(); return a collection of values
remove(key)
clear()
putAll(Map<? extends k, ? extends v> map)
LinkedHashMap: (ordered)
keeping insertion order.
TreeMap
TreeMap implements the NavigableMap interface, which extends the SortedMap interface. TreeMap is sorted in its natural order(implemented Comparable interface), or sorted according to any external custom comparator in many ways.
SortedMap
SortedMap is an interface, offering APIs taking use of sorted elements; for instance, you may easily Finding the min. and max. from a sorted map.
K firstKey();
K lastKey();
Copying a portion of Map from fromKey(included) and toKey(excluded).
SortedMap<K, V> subMap(K fromKey, K toKey): >=fromKey AND <toKey
Copying a portion of Map, whose keys are strictly less toKey
SortedMap<K,V> headMap(K to): <
Copying a portion of Map from the tail, whose keys are strictly greater than fromKey
SortedMap<K,V> tailMap(K from): >
NavigableMap offers APIs to search key-value, like lower(), floor(), higher(), and ceiling()
lowerKey(Key): < key
floorKey(Key): <=key
higherLey(Key): > key
ceilingKey(Key): >=key
descendingMap(): returns a NavigatbleMap in a reverse order
pollFirstEntry(): return and remove the first entry.
pollLastEntry(): return and remove the last entry.