Wednesday, 31 August 2016
How to define immutable class
for protecting shared data, it is a way to hold it in an immutable class.
how to create an immutable class
(1) Having no setters.
(2) private fields, and make it final; so it will be init. only once.
(3) final class;
Tuesday, 30 August 2016
TreeSet accept only Comparable Elements
Elements that are added into TreeSet must be Comparable, implementing Comparable interface; or transferring a Comparator that implements Comparator interface via TreeSet argument, i.e.
public TreeSet(Comparator comparator)
The underlying reason; TreeSet is implemented as a black-red tree, it always compares two elements, and knowing bigger or smaller in order to put a bigger one in the right sub-tree of a root node, but a smaller one on the left side.
If you don't add a comparable element in the TreeSet, then getting a compiling error.
Why HashSet is called Hash Set?
HashSet is one of concrete implementations for Set interface. Internally, it is implemented by a HashMap. So it uses a key-value pair to store elements, i.e. element's hash code and element itself. Please note here: hash code internally will be transferred into an index number by an equation. It is not hashcode directly become a key. So on this case, HashSet may not guarantee the order, and different hashcode might converted into the same index number. On that case, equality measurement will be incurred.
When adding an element into the HashSet collection, the element's hashcode method will be invoked, and hashcode will be used to determine which bucket allocated in the set. As two elements have the same hashcode, then the equals method will be called, in order to determine the uniqueness of the inserted elements. If they are not equal, then they both are added, even they have the same hash number.
The underlying implementing HashSet, is using hash number as its key in the map. This makes value retrieving efficient, meanwhile using equals method to guarantee the set won't have duplicated elements.
So, as using HashSet, you may need to override the equals and hashCode methods. The following shows an experiment, when hashCode and equals method are not overridden.
When adding an element into the HashSet collection, the element's hashcode method will be invoked, and hashcode will be used to determine which bucket allocated in the set. As two elements have the same hashcode, then the equals method will be called, in order to determine the uniqueness of the inserted elements. If they are not equal, then they both are added, even they have the same hash number.
The underlying implementing HashSet, is using hash number as its key in the map. This makes value retrieving efficient, meanwhile using equals method to guarantee the set won't have duplicated elements.
So, as using HashSet, you may need to override the equals and hashCode methods. The following shows an experiment, when hashCode and equals method are not overridden.
public class Book {
private String name;
public Book() {
}
public Book(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString(){
return this.name;
}
}
When inserting several books with the same name, what happens? for hashCode method is not overridden, they give different hashcode, and therefor books will be considered different.
public class HashSetHash {
public static void main(String[] args) {
Set myBooks = new HashSet<>();
myBooks.add(new Book("Java Generics and Collections"));
myBooks.add(new Book("Java Generics and Collections"));
myBooks.add(new Book("Java Generics and Collections"));
System.out.println(myBooks);
}
}
From output, 3 same books are in the set.
run: [Java Generics and Collections, Java Generics and Collections, Java Generics and Collections] BUILD SUCCESSFUL (total time: 0 seconds)If overriding equals method by adding the following code in the Book class
@Override
public boolean equals(Object object) {
if (object instanceof Book) {
return this.name.equals(((Book) object).getName());
}
return false;
}
Then what is output? the three books should still be added. On this moment, for 3 different Book instances, so they still have different hashcode; for HashSet, it uses hashCode to determine uniqueness first, but not the equals methods. In another, the equals method will be called later, when instances get the same hash code; So we still see the same output.
run: [Java Generics and Collections, Java Generics and Collections, Java Generics and Collections] BUILD SUCCESSFUL (total time: 0 seconds)Now let's overriding the hashCode method, and adding the following code in Book class.
@Override
public int hashCode() {
int hash = 7;
hash = 41 * hash + Objects.hashCode(this.name);
return hash;
}
It shows that the hash code depends on the book name; so when the same book names, they gives the same hash code. The HashSet will put the first book in the bucket, then invoking equals method to determine rest two are duplicated. Certainly, the rest elements may not equal, in other cases, then they will be put in bucket following the first.run: [Java Generics and Collections] BUILD SUCCESSFUL (total time: 0 seconds)
Monday, 29 August 2016
Init. BigDecimal using string or float can give differences
It may initialize a BigDecmal by its constructor. However, it may leave difference as using float type or string type.
The following experiment is able to approve it. You will see init. by the string gives the exactly same result, but using float will lead to a slight bias.
The following experiment is able to approve it. You will see init. by the string gives the exactly same result, but using float will lead to a slight bias.
import java.math.BigDecimal;
/**
*
* @author YNZ
*/
public class UsingStringInit {
public static void main(String[] args) {
float f = 1000.1f;
BigDecimal bf = new BigDecimal(f);
System.out.println("" + bf);
double d = 1000.1d;
BigDecimal bdd = new BigDecimal(d);
System.out.println("" + bdd);
String val = "1000.1";
BigDecimal dd = new BigDecimal(val);
System.out.println("" + dd);
}
}
run: 1000.0999755859375 1000.1000000000000227373675443232059478759765625 1000.1 BUILD SUCCESSFUL (total time: 0 seconds)The interesting is the decimal number "1000." will not exactly presented as BigDecimal is initialized by the float type.
Saturday, 27 August 2016
What difference between element, peer and poll of Queue
In a Queue, element is added at the tail and retrieved from the head.
using 'add' and 'offer' to add element on tail.
using 'element' 'peer' and 'poll' to retrieve element on head.
Difference
'element' and 'peer' are able to retrieve the head, but don't remove it; but for 'pool', which retrieving head and removing it .
In Java, LinkedList implements Queue interface; in another word, Queue is implemented by the LinkedList.
/**
*
* @author YNZ
*/
public class UseLinkedList {
public static void main(String[] args) {
LinkedList linkedPersons = new LinkedList<>();
Random r = new Random();
char a = 'A';
for (int i = 1; i < 4; i++) {
if (a > 'Z') {
break;
}
String name = String.valueOf(a).concat(String.valueOf(a));
linkedPersons.add(new Person(name, r.nextInt(100)));
a++;
}
Queue queue = linkedPersons;
System.out.println("Initial Q = " + queue);
Person head = queue.element();
System.out.println("after element = " + head);
System.out.println("Q = " + queue);
Person peek = queue.peek();
System.out.println("after peek = " + peek);
System.out.println("Q = " + queue);
Person poll = queue.poll();
System.out.println("after poll = " + poll);
System.out.println("Q = " + queue);
}
}
run:
Initial Q = [AA 42, BB 46, CC 72]
after element = AA 42
Q = [AA 42, BB 46, CC 72]
after peek = AA 42
Q = [AA 42, BB 46, CC 72]
after poll = AA 42
Q = [BB 46, CC 72]
BUILD SUCCESSFUL (total time: 0 seconds)
How hibernate works
Or what it can do? Hibernate, residing on the application layer, supporting business logic.
- Mapping Java classes (Entity) with Tables in database.
- Mapping entity instances within table entries.
- Mapping an entity property within table fields
- Implementing persistence crude operations, and hiding complexity of SQL.
- Maintain transactions
- Maintain dirty checking
Hibernate manages how database connected, and data persisted via Entity manager. So for setting/configuring hibernate, "persistence.xml" is critical, which tells database URL, name, password, and mapping classes, and it may describe more than one database connection. One entity manager corresponds to one persistence unit.
Wednesday, 24 August 2016
hibernate jpa
Hibernate is the first solution for ORM, not the JPA. Later on, Sun makes it included in the java technique.
So there is no big difference between Hibernate and JPA actually, but Hibernate owned by the JBoss individually. JPA is a Java community standard.
Hibernate implement oracle JPA standard now, just like many other vendors which offer the JPA implementations. However, Hibernate is the most popular JPA implementation so far. Normally we call it Hibernate-JPA.
there is a slight difference between classical Hibernate and Hibernate JPA. The main part is much easier to declare a context in the JPA. there is no session any more, but only need the Persistence to create EntityFactory in line with persistence.xml, and via which we may easily build Entity manager.
The entity manager is the core part of implementing ORM persisting and retrieving data between objects in java and database tables.
From the Entity manager we may declare a transaction to start, and then do data crude operations, and commit transactions. Finally, the entity manager needs to close.
The mapping annotation actually there is no difference, and crud method names have been renamed. for instance, in classical Hibernate session save has been renamed as entity manager persist; and session get has been renamed as entity manager find.
So there is no big difference between Hibernate and JPA actually, but Hibernate owned by the JBoss individually. JPA is a Java community standard.
Hibernate implement oracle JPA standard now, just like many other vendors which offer the JPA implementations. However, Hibernate is the most popular JPA implementation so far. Normally we call it Hibernate-JPA.
there is a slight difference between classical Hibernate and Hibernate JPA. The main part is much easier to declare a context in the JPA. there is no session any more, but only need the Persistence to create EntityFactory in line with persistence.xml, and via which we may easily build Entity manager.
The entity manager is the core part of implementing ORM persisting and retrieving data between objects in java and database tables.
From the Entity manager we may declare a transaction to start, and then do data crude operations, and commit transactions. Finally, the entity manager needs to close.
The mapping annotation actually there is no difference, and crud method names have been renamed. for instance, in classical Hibernate session save has been renamed as entity manager persist; and session get has been renamed as entity manager find.
Thursday, 11 August 2016
Actor Model
Actor model is not a new concept.
What is Actor? it includes state and behaviors, like a Class. The difference lies at Actor owns a mail box, which receives messages in an order. A actor is associated with a event-driven thread. It hands mails one by one, in a re-active, or lazy way.
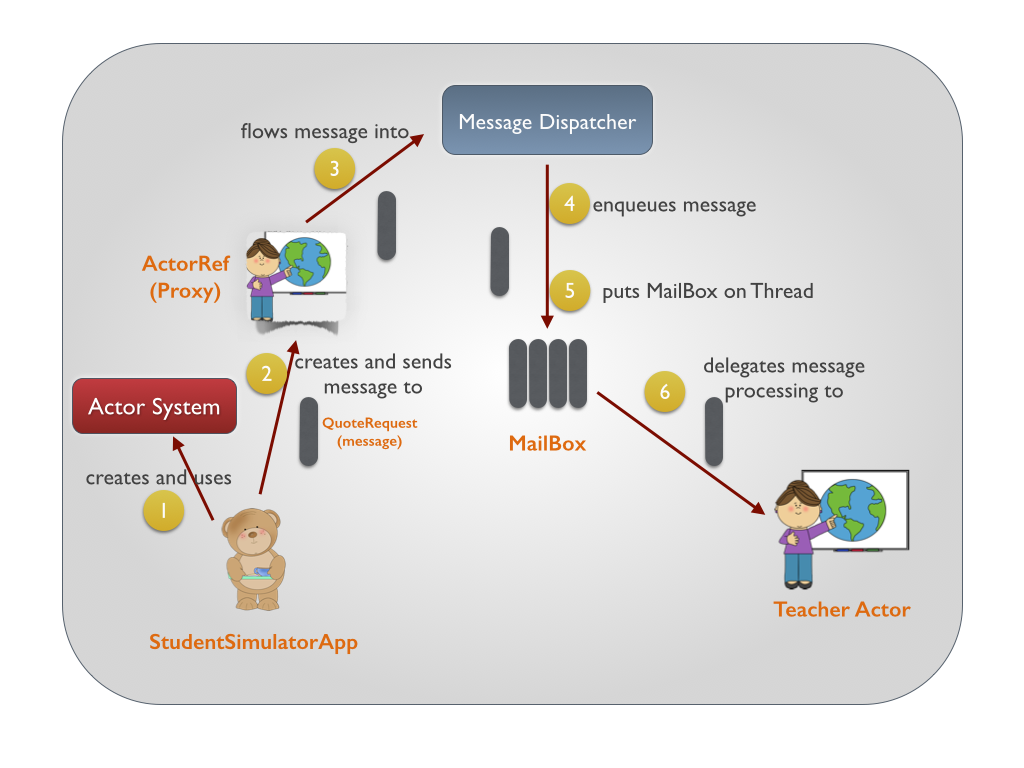
Tuesday, 9 August 2016
configuring Derby database into client-server model
Derby may run 3 model, i.e. embedded, client-server and net. In spring-boot, you need specific setting up, so that Derby may run in client-server model. Otherwise, it will choose run in a embedded mode.
POM dependency
<dependency>
<groupId>org.apache.derby</groupId>
<artifactId>derbyclient</artifactId>
<version>10.12.1.1</version>
</dependency>
And in application.properties adding followings:
POM dependency
<dependency>
<groupId>org.apache.derby</groupId>
<artifactId>derbyclient</artifactId>
<version>10.12.1.1</version>
</dependency>
And in application.properties adding followings:
spring.datasource.url=jdbc:derby://localhost:1527/test spring.datasource.username=YNZ spring.datasource.password=YNZ spring.datasource.initialize=false spring.datasource.driver-class-name= org.apache.derby.jdbc.ClientDriver spring.jpa.database-platform = org.hibernate.dialect.DerbyDialect
Subscribe to:
Comments (Atom)
-
 Could not extract response: no suitable HttpMessageConverter found for response type [class dk.enettet.evu.core.model.Address] and content ...
Could not extract response: no suitable HttpMessageConverter found for response type [class dk.enettet.evu.core.model.Address] and content ... -
In construction. Spring test annotations: @SpringBooTest @DataJpaTest @TestPropertySource @ActiveProfiles @Sql @SpringBootTest It is used f...
-
First time met this hibernate exception. I think this issue should due to one to one relationship. One driver has one car; one car has on...